Redis string 底层数据结构以及典型的API
数据结构
底层结构 redisObject + SDS 的介绍
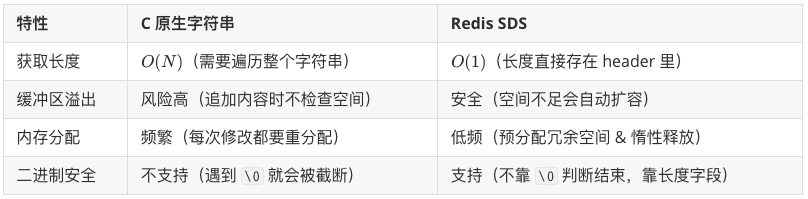
为什么不用 C 语言原生字符串? SDS(Simple Dynamic String)记录了长度信息,它的获取长度复杂度为 $O(1)$,且支持空间预分配和惰性空间释放,避免了频繁的内存重分配,保证了二进制安全。
编码优化:小整数会编码为 int,短字符串(<=44字节)编码为 embstr。Redis 默认使用
jemalloc作为内存分配器,它分配内存时是按块给的。最常用的一个小块大小是 64 字节。为了极致利用这 64 字节,不浪费一丁点儿空间,redis将短字符串编码为 embstr。你可以把 SDS 想象成装水的杯子,而 embstr 是 “杯子” 和 “键值对说明标签 redisObject” 的组合 ,省得你再分两次从内存读写数据。44 是因为 “SDS sdshdr8 类型的 hrader”+\0和 “redisObject” 一共占了 20(3+1+16) 字节,剩下的 44 字节刚好凑够 64 字节的一整块内存。
对字符串的处理,相比于redis 的 SDS,C语言的字符串着实显得很“笨”,它只是一串字符并以空字符 \0 结尾,而 SDS 在内存结构上多了一些“元数据”,下面是两种字符串的一些对比:
SDS 的物理结构是怎样的?
在 Redis 3.2 版本之后,为了针对不同长度的字符串进一步节省空间,SDS 被拆分成了 5 种不同的结构体:
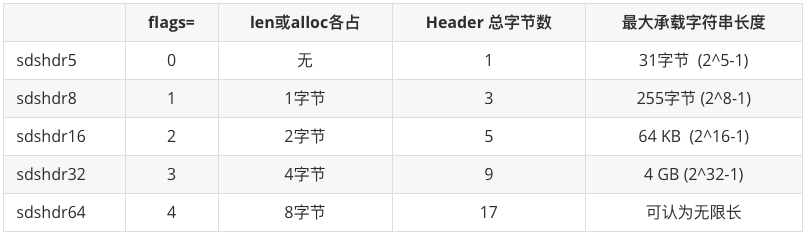
注1:Header = len + alloc + flags;
注2:sdshdr5 是极短字符串,只有它不带len和alloc,长度存在flags的高5位(低三位存flags),现在很少用。
不同的 sdshdr(5, 8, 16, 32, 64)本质上是为了给不同长度的字符串量身定制“管理头”。以最常用的 sdshdr8(存储 256 字节以内的字符串)为例:
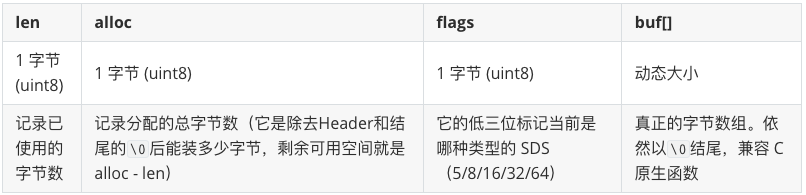
如果是 sdshdr16:len 和 alloc 各占 2 字节。
如果是 sdshdr64:len 和 alloc 各占 8 字节。
使用5中不同的结构体(flags区分),这么设计的意义在于:
- 极致的内存压缩(节省开销):如果是一个只有 5 字节的字符串 “Redis”,在旧版本里 len 和 alloc 可能固定占 8 字节。而现在的 sdshdr8 模式下,元数据只占 3 字节(len+alloc+flags),对于拥有数亿个 Key 的 Redis 实例来说,每个 Key 省几个字节,加起来就是省下几个 GB 的内存。
- 空间预分配 (Spatial Pre-allocation):当对 SDS 进行修改(如追加字符串)时,Redis 不仅仅分配刚刚好的空间,而是会多分配一些:修改后长度 < 1MB,那么就分配 x2 长度的空间;修改后长度 >= 1MB,就额外多分配 1MB 的空闲空间,减少频繁修改字符串导致的系统调用和内存重分配次数。为什么阈值是
1MB呢?因为针对小字符串,加倍分配不会浪费太多内存(比如 10 字节变 20 字节),但收益极高。针对大字符串,如果字符串已经 100MB 了,再加倍就是 200MB,太浪费了!所以当长度超过 1MB 时,Redis 每次只额外多给 1MB 的空间,作为缓冲。
一个简单的字符串增长示例
举一个简单的例子来说明字符串增长的这个过程:
假设你现在有一个 Redis Key,初始值是字符串 “Redis”。
- 第一阶段(初始化):你存入 “Redis” (5个字节),此时 len=5、alloc=5、buf=[‘R’, ‘e’, ‘d’, ‘i’, ‘s’, ‘\0’],没有多余空间
- 第二阶段(追加内容 触发预分配):现在你执行 APPEND 命令,想加上 “ 6.0” (共 4 个字节,含空格)。那么就会 计算新长度 5 + 4 = 9 字节,因为 9 < 1MB,Redis 会分配 9 x 2 = 18 字节的容量,更新后状态:len=9、alloc=18、buf=[‘R’, ‘e’, ‘d’, ‘i’, ‘s’, ‘ ‘, ‘6’, ‘.’, ‘0’, ‘\0’, …后面还有9个空位]
- 第三阶段(再次追加):如果你接着追加 “ Best” (5 个字节)。计算新长度 9 + 5 = 14 字节,发现 alloc(18) 足够容纳 14 字节,直接写入,无需向操作系统申请内存内存扩容。最后 len = 14、alloc=18(维持不变)。
如果按照 C 语言的逻辑,每次 APPEND 都要申请一块新内存,拷贝旧数据到新内存,释放旧内存。这涉及系统调用,在高性能高并发的 Redis 中是非常昂贵的开销。Redis 的逻辑是:既然你修改了字符串,说明你以后可能还会改。我干脆多给你一倍的空间,下次你再改的时候,如果空间够用,我就直接在内存里原地写。将连续修改 $N$ 次字符串所需的内存分配次数,从 N 次 降低为 最多 N 次(实际通常远少于 N 次)。
典型的应用
缓存、计数器、分布式锁。
string API
1 | # 基础操作 |
关于 redis TTL
TTL的原理
Redis 并不是为每个设置了 TTL(生存时间)的 Key 都开启一个定时器,那样会极其消耗 CPU。它采用的是 ”定期删除 + 惰性删除“ 两种策略的结合。
- 定期删除 (Active Way):Redis 内部每秒进行 10 次(默认的配置
hz 10)例行检查。- 从设置了过期的 Key 集合中随机抽取 20 个 Key。
- 删除这 20 个中已过期的 Key。
- 如果过期的 Key 占比超过
25%,则重复步骤 1。
- 惰性删除 (Passive Way):当客户端尝试访问某个 Key 时,Redis 会先检查这个 Key 是否已过期。如果过期了,立刻删除它并返回空;如果没有过期,返回数据。这对 CPU 极度友好,只有在用到时才处理。但如果大量 Key 过期后从未被访问,它们会一直霸占内存,造成内存泄漏。所以还要结合 “定期删除” 的策略才能达到较好的效果。
如何避免同时出现大规模过期key?
如果你的 Key 过期时间是随机分布的(比如用户 Session 随机在 30~60 分钟过期),Redis 能够轻松应对,负载几乎感觉不到。但如果你在程序里写了 SET key val EX 3600,且在某一秒钟内产生了几万个这样的 Key。一小时后,这些 Key 会同时过期。这会导致Redis 的 “定期删除” 循环会发现过期占比一直高于 25%,从而不断触发循环。由于 Redis 是单线程的,结果 Redis 忙于删除过期数据,产生明显的延迟。为了保证系统在高并发下的平滑,建议采取以下策略:
给过期时间加随机扰动: 不要让大量 Key 在同一秒失效。在设置过期时间时,加上一个随机数。
1
2
3
4# 坏做法:
EXPIRE key 3600
# 好做法:
EXPIRE key (3600 + random(1, 300))监控内存淘汰 (Eviction): 如果内存满了,Redis 会触发 maxmemory-policy(例如配置了 allkeys-lru) 策略强制删数据,这比过期删除更消耗性能。请确保 maxmemory 留有余地,默认 # maxmemory \<bytes> ,在 64 位系统上不限制内存使用,而在 32 位系统上隐式限制为 3GB。建议生产环境设置一个硬上限,否则一旦 Redis 内存耗尽了的物理内存,就会触发 OOM Killer 直接杀掉 Redis 进程。
1
2
3
4# 设置 Redis 最大占用 4GB 内存 (根据你服务器实际内存调整)
maxmemory 4gb
# 设置达到上限后的处理策略 (最推荐策略)
maxmemory-policy allkeys-lru调整 active-expire-effort (Redis 6.0+): 如果你确实有海量过期需求,可以适当调大这个参数(默认 1),让 Redis 在后台更积极地处理过期,但要注意这会稍微提升 CPU 占用。